
Microsoft terus meningkatkan percakapan dengan menghadirkan model terbarunya, kondisi phi-4, phi-4-rasoning-plus dan phi-4-mini-razoning.
Era baru AI
Setahun yang lalu, Microsoft memperkenalkan Model Bahasa Kecil (SLM) kepada pelanggan dengan peluncuran Phi-3 di dalam AI AI FunditionMengambil keuntungan dari penelitian SLM untuk memperluas jangkauan model dan alat yang efisien yang tersedia untuk pelanggan.
Hari ini kami sangat senang hadir Phi-4-razoning, phi-4-razoning-plus dan phi-4-mini-razoning—Memari era baru untuk model bahasa kecil dan sekali lagi mendefinisikan kembali apa yang mungkin dengan AI kecil dan efisien.
Model penalaran, langkah maju selanjutnya
Model penalaran Mereka dilatih untuk mengambil keuntungan dari skala waktu inferensi untuk melakukan tugas -tugas kompleks yang membutuhkan dekomposisi beberapa langkah dan refleksi internal. Mereka menonjol dalam penalaran matematika dan muncul sebagai tulang punggung aplikasi agen dengan tugas yang kompleks dan beragam. Kemampuan ini umumnya hanya ditemukan dalam model perbatasan besar. Model penalaran PHI memperkenalkan kategori baru model bahasa kecil. Menggunakan distilasi, pembelajaran penguatan dan data berkualitas tinggi, model ini menyeimbangkan ukuran dan kinerja. Mereka cukup kecil untuk lingkungan latensi rendah, tetapi mereka mempertahankan kemampuan penalaran yang kuat yang menyaingi model yang jauh lebih besar. Campuran ini memungkinkan bahkan perangkat yang terbatas untuk sumber daya untuk melakukan tugas penalaran yang kompleks secara efisien.
Penalaran phi-4 dan phi-4 lebih banyak penalaran
PHI-4 Penalaran Ini adalah model penalaran bobot terbuka dari 14 miliar parameter yang menyaingi model yang jauh lebih besar dalam tugas penalaran yang kompleks. Dilatih melalui penyesuaian halus yang diawasi dengan baik dalam demonstrasi penalaran Openai O3-mini yang dipilih dengan cermat, phi-4-rasioning menghasilkan rantai penalaran terperinci yang secara efektif memanfaatkan perhitungan waktu inferensi tambahan. Model ini menunjukkan bahwa penyembuhan data yang cermat dan set data sintetis berkualitas tinggi memungkinkan model yang lebih kecil untuk bersaing dengan rekan yang lebih besar.
PHI-4-RAZONING-PLUS didasarkan pada kemampuan lalu lintas phi-4, bahkan lebih terlatih dengan penguatan pembelajaran untuk menggunakan lebih banyak inferensi inferensi, menggunakan 1,5 kali lebih banyak token daripada mengemudi Phi-4, untuk menawarkan presisi yang lebih besar.
Meskipun ukurannya secara signifikan lebih kecil, kedua model mencapai kinerja yang lebih baik seperti O1-Mini dan Deepseek-R1-Distill-Llama-70B di sebagian besar titik referensi, termasuk penalaran matematika dan Ph.D. Pertanyaan Sains Level. Mereka mencapai kinerja terbaik daripada model penuh Deepseek-R1 (dengan 671 miliar parameter) dalam tes AIME 2025, kualifikasi 2025 untuk Olimpiade Matematika AS. UU. Kedua model tersedia di AI AI Fundition dan Huggingface.
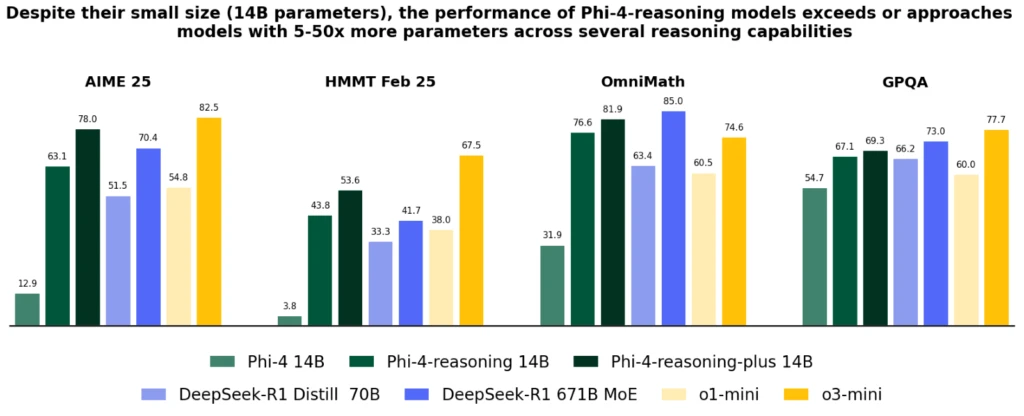

Model kondisi Phi-4 memperkenalkan peningkatan penting pada pHI-4, melebihi model terbesar seperti Deepseek-R1-Distill-70B dan mendekati Deep-R1 dalam beberapa penalaran dan penalaran umum, termasuk matematika, pengkodean, resolusi masalah dan perencanaan algoritmik. Dia Laporan Teknis Ini memberikan bukti kuantitatif yang luas dari perbaikan ini melalui berbagai tugas penalaran.
Phi-4-mini-razonation
Phi-4-mini-razonation Ini dirancang untuk memenuhi permintaan untuk model penalaran yang ringkas. Model bahasa berbasis transformator ini dioptimalkan untuk penalaran matematika, memberikan masalah berkualitas tinggi dan langkah demi langkah di lingkungan dengan komputasi atau latensi terbatas. Avites dengan data sintetis yang dihasilkan oleh model Deepseek-R1, efisiensi konstruksi phi-4-mini dengan kapasitas penalaran lanjutan. Ini sangat ideal untuk aplikasi pendidikan, bimbingan belajar yang terintegrasi dan implementasi cahaya di edge atau sistem seluler, dan dilatih dalam lebih dari satu juta masalah matematika yang beragam yang mencakup berbagai tingkat kesulitan dari sekolah menengah ke Ph.D. tingkat. Coba modelnya AI AI Fundition salah satu Memeluk wajah Hari ini.
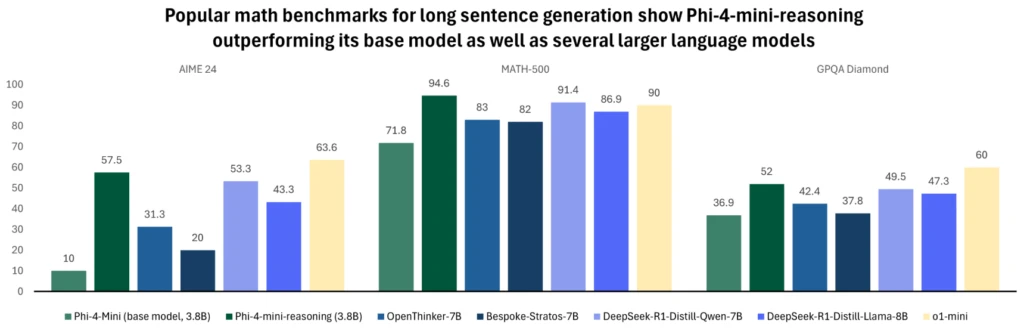
Untuk informasi lebih lanjut tentang model, bacaLaporan Teknis yang memberikan ide kuantitatif tambahan.
Evolusi PHI selama tahun lalu terus mendorong kualitas ini terhadap ukuran, memperluas keluarga dengan karakteristik baru untuk memenuhi berbagai kebutuhan. Pada skala perangkat Windows 11, model ini tersedia untuk dijalankan secara lokal di CPU dan GPU.
Karena Windows berfungsi untuk membuat jenis PC baru, model PHI telah menjadi bagian integral dari co -pilot+ PC dengan optimasi NPU Varian Phi Silica. Versi yang sangat efisien dan dikelola oleh sistem operasi PHI ini dirancang untuk dimuat dalam memori, dan tersedia dengan waktu cepat untuk tanggapan token pertama dan kinerja token yang efisien sehingga dapat dipanggil secara bersamaan dengan aplikasi lain yang dieksekusi pada PC -nya.
Itu digunakan dalam pengalaman sentral seperti Klik untuk dilakukanmenyediakan alat intelijen teks yang berguna untuk konten apa pun di layar Anda, dan tersedia sebagai API Pengembang Untuk dengan mudah diintegrasikan ke dalam aplikasi, karena digunakan dalam beberapa aplikasi produktivitas seperti Outlook, menawarkan karakteristik ringkasan co -ilot yang keluar -line. Model -model kecil namun kuat ini telah dioptimalkan dan diintegrasikan untuk digunakan dalam beberapa aplikasi melalui luasnya ekosistem PC kami. Model phi-4-rasoning dan phi-4-mini-razoning memanfaatkan optimasi rendah-bit untuk PHI silika dan akan tersedia untuk segera bekerja di co-pilot+ NPU PC.
Keamanan dan pendekatan Microsoft untuk AI yang bertanggung jawab
Di Microsoft, AI bertanggung jawab Ini adalah prinsip mendasar yang memandu pengembangan dan penyebaran sistem AI, termasuk model PHI kami. Model PHI berkembang sesuai dengan prinsip -prinsip Microsoft AI: tanggung jawab, transparansi, ekuitas, keandalan dan keamanan, privasi dan keamanan, dan inklusi.
Keluarga model PHI telah mengadopsi pendekatan keamanan yang kuat setelah keamanan, mengambil keuntungan dari kombinasi penyesuaian baik yang diawasi (SFT), optimalisasi preferensi langsung (DPO) dan penguatan pembelajaran teknik umpan balik manusia (RLHF). Metode -metode ini menggunakan beberapa set data, termasuk set data yang tersedia untuk umum berfokus pada bantuan dan tidak berbahaya, serta beberapa pertanyaan dan jawaban keamanan. Sementara keluarga model PHI dirancang untuk melakukan berbagai tugas secara efektif, penting untuk mengenali bahwa semua model AI dapat menunjukkan keterbatasan. Untuk lebih memahami keterbatasan ini dan langkah -langkah yang ditetapkan untuk mengatasinya, lihat kartu model di bawah ini, yang memberikan informasi terperinci tentang praktik dan pedoman yang bertanggung jawab.

